Introduction
Languages have always fascinated me.
I remember my first exposure to a foreign language when I was 7 or 8, on holiday in French Catalonia with my parents. We attended a concert sung in Catalan and the booklet provided before the concert contained lyrics both in French and Catalan. Since both are roman languages and are relatively similar, I could read and understand some Catalan words, and I started trying to decipher other unknown words by comparing the two versions. I kept this booklet for a long time, and although I never became fluent in Catalan, at least it triggered an interest which I never lost.
An interesting point about languages is how, even without speaking them well, one can often quickly identify whether words belong to that language or not. Each language has patterns and once you know a few of them, telling a language from another becomes easy. Of course if you never been confronted to a language before, that’s not possible to identify it. Great example of supervised learning ;)
Just for fun I decided to analyze the frequency of sequences of letters in French and Russian, and see if it can help forge words from these two languages. This is what this post is about.
Letters sequence analysis
As a source of data I used dictionaries. I read them entirely, and I recorded the frequency of each two and three letters sequences (called 2-grams and 3-grams). I stored these data in a cube with on x-axis the first letter, on y-axis the second letter and on z-axis the third letter. Each value in the cube is the count of how many times the sequence occurs. After normalizing the values to obtain probabilities, the cube can easily be flatten to two dimensions so it can be visualized.
This is what the result looks like:
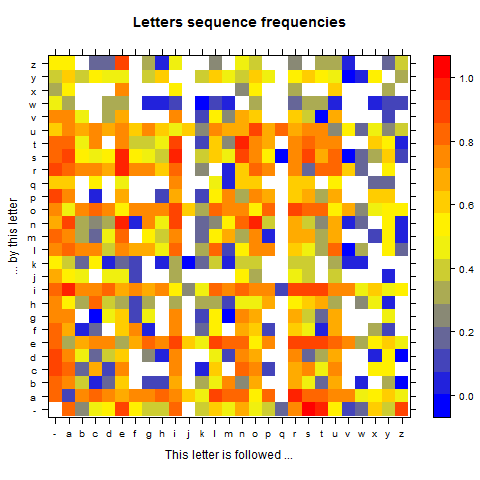
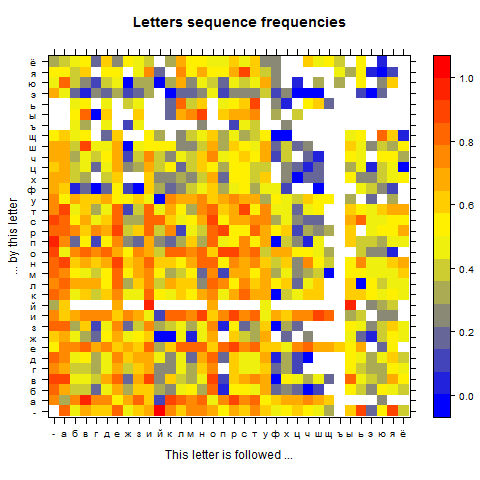
Note that the frequency is on a log scale in order to better highlight the different probabilities (otherwise some too extreme high values tend to kill readability), so the absolute values are hard to interpret, however the colors speak for themselves:
- white: sequence does not exist
- blue: sequence is rare
- red: sequence is frequent
It’s interesting to see that in both languages, some sequence never occur, whereas other are extremely frequent. For instance in French, “q” is mostly followed by “u”, very rarely by “s” or “i”, sometimes it finishes the word, and that’s it. No other letter ever appears after q.
It’s interesting to look at the diagonal (starting bottom left and going to top right): it shows how frequently letters are repeated. In French, it turns out only 7 letters never appear twice in a row: “h”, “j”, “q”, “v”, “w”, “x”, “y”. The letter that follows itself most frequently is “s”.
There are many conclusions you can make by studying the matrix. These are just two illustrations of patterns you unconsciously learn when you read a language.
Words generation
With our table of frequencies at hand, we can run a markov chain to generate words that look like French or Russian words.
I just had to pick a first letter based on its relative frequency as the first letter of a word, and then keep choosing letters based on their relative occurrence frequency based on the previous two letters in the word created.
There is no real complexity here. The most difficult part of the implementation was to deal with special characters. French has a lot of accents (é, è, à, ù etc) and Russian is obviously using Cyrillic alphabet, not Latin.
The result looks good and can easily be used to generate new vocabulary. Sometimes an actual word from the dictionary is generated.
The Word-o-Tron in action
I implemented the Word-O-Tron using R and Shiny. The code is available on github and the application itself on shiny server
The result is a totally useless, however fun application :)