Background
Over the past decades, the amount of video content available to watch has literally boomed.
From a handful TV channels in the eighties, people now have the choice between hundreds of TV channels, over 1 billion YouTube videos and nearly the whole history of movies and series on Netflix or other paying streaming platforms.
In this context, standing out as a content producer or finding out what to watch as a “consumer” has become harder and harder. As a result recommendations systems have become crucial in this new content jungle. It helps improve visibility of content which results in more views, and helps the public to identify more easily content they will enjoy.
But one question one might ask in the first place is obviously, what makes a movie successful?
Goals and method
In this week’s project, we intend to analyse the criteria that impact movie ratings.
IMDB (Internet movie database) is a website launched in 1996 where internet users can rate and comment movies, TV series and other video contents such as documentaries.
Based on the list of the 250 best rated movies on IMDB, plus a user list of 1000 best movies, plus some movies picked randomly in IMDB, we will observe various features and identify which ones play a role in the movie sucess. We intend to identify a few of these features in order of importance, and produce a recommendation for film producers so they know how to enhance their future movies ratings.
The features we will study are:
- year of release
- duration (in minutes)
- genre (Drama, Romance etc)
- main actor
- director
Risks and assumptions
It is worth noting that IMBD belongs to Amazon, a company that intends to become a major player on the streaming market, and therefore a direct competitor of Netflix (just to name this one).
As a content provider, ratings provided by Amazon may be biased since the company has an interest in highly rating movies so they are watched by more people, and hence generating more revenue.
Such a biased has been observed and well documented for the Fandango review web site, see the article on FiveTheiryEight website
Other data sources may also provide different movie ratings and therefore the studied information should be considered not as the sole version of the truth, but rather a biased version of it.
Finally, we assume that the information recorded and made available to us by IMBD, in particular the movie features (director, actors, date of release etc) are accurate.
Results
Let’s look at a few features from our movie set.
Movies interesting features
Movies by rating
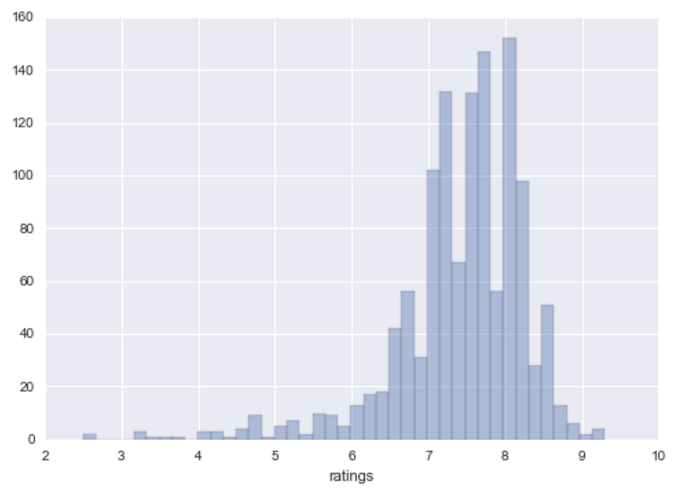 The data is clearly skewed to the right, i.e. we have much more movies with a rating higher than the average theoretical rating (5).
The data is clearly skewed to the right, i.e. we have much more movies with a rating higher than the average theoretical rating (5).
This was expected since most our movies are part of “best of” lists
Movies by duration
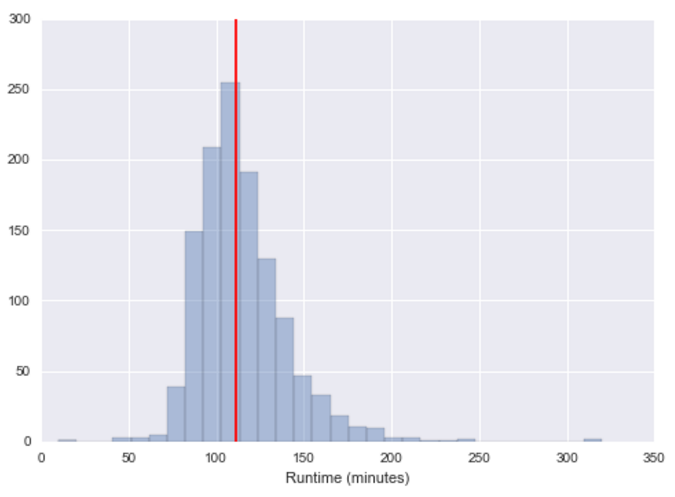 The median value is 120 minutes, i.e. two hours. Movies are fairly normally distributed around this value.
The median value is 120 minutes, i.e. two hours. Movies are fairly normally distributed around this value.
Duration by genre
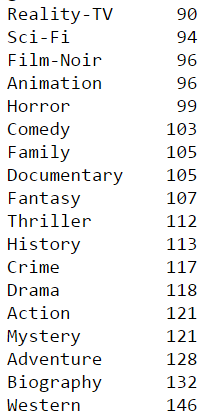 There are clear differences between genres, with some running usually around 1 hour 30 minutes (Film Noir, Animation) whereas others are closer to 2 hours 30 minutes (western)
There are clear differences between genres, with some running usually around 1 hour 30 minutes (Film Noir, Animation) whereas others are closer to 2 hours 30 minutes (western)
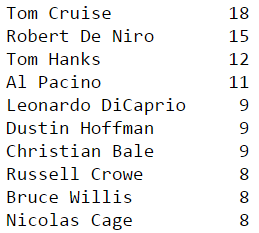
Most popular actors
Most popular directors
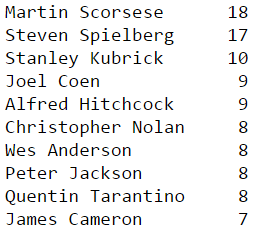
Interestingly the second most popular actor has worked a lot with the most poopular director… indeed De Niro has acted in many Scorsese movies, including “Taxi Driver” or “Casino” to name just these ones.
Likewise the most popular actor has worked with the second most popular director. Tom Cruise was staring in “Minority Report” or “War of Worlds” by Spielberg.
My suggestion to Hollywood producers was going to be this: bring Tom Cruise and Martin Scorsese together on the same film… it would undoubtly become a smashing hit! But actually I then realised such as movie was shot in 1986: “The Color of Money”. But is only rated 7 on IMBD… something must have gone wrong here!
Predicting very high scores
We will now attempt to predict the top 20% best movies (80th percentile) based on our sample. This corresponds to scores greater or equal to 8.2
Predicting very high scores with a decision Tree
Accuracy: 0.87
F1-score: 0.85
Confusion Matrix
| predicted < 8 | predicted >= 8 | |
|---|---|---|
| is < 8 | 336 | 10 |
| is >= 8 | 40 | 10 |
Predicting very high scores with a decision boosting Tree
Accuracy: 0.99
F1-score: 0.99
Confusion Matrix
| predicted < 8.2 | predicted >= 8.2 | |
|---|---|---|
| is < 8.2 | 345 | 1 |
| is >= 8.2 | 4 | 46 |
Interpretation
We built two models that try to predict whether the IMDB score of the movie is going to be equal or higher than 8.2, or lower.
Both models perform reasonably well at this job. Let’s look at them in more details.
Simple decision tree
The simple decision tree has the advantage of leading to a very interpretable result. However its prediction capacities are slightly below the boosting tree.
The tree looks like this:
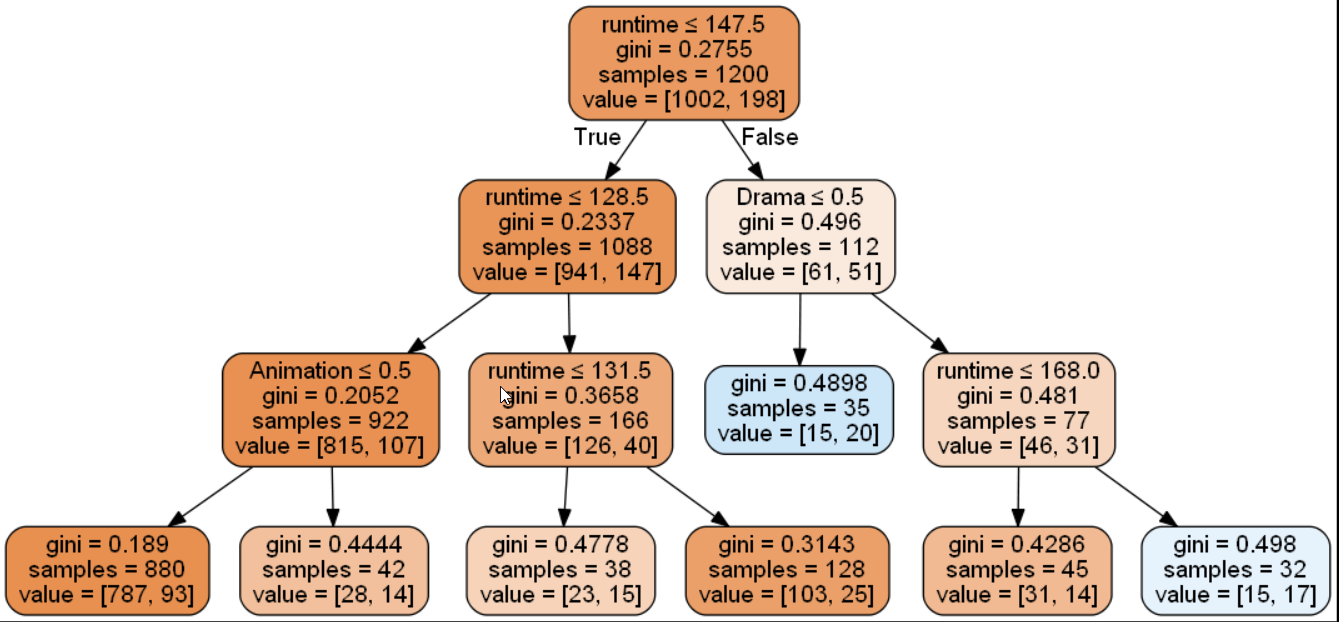
It might be a bit daunting to read at first, but what it tells us is this (amongst other things):
- if you are a drama that last over 168 minutes, you nearly have 50% chances to get a very high rating
- if you are not an animation and last less than 128 minutes, you have 89% chances to not be get high rating
This models however is not very good at capturing which movies is best rated. When it predicts one, it is only right 50% of the time, and overall it misses to identify 50% of highly rated movies.
It does a better job at identifying which movies won’t be highly rated. It captures 97% of them. And in 11% of the cases it is wrong, and the movie actually scored very high.
Boosting tree
Boosting tree unfortunately doesn’t allow easy interpretation. It cannot be mapped under a form that can simply be understood.
However its results are superior. Basically in our movies list, it was able to predict with 99% confidence when a movies would be below 8.2, and 98% which ones would be above 8.2.
And overall it predicted 100% of below 8.2 and 92% of above 92.
Conclusion
The models we build were extremely simple and yet allowed to flag with a fairly good accuracy which movies would score more or less than 8.2 in IMDB, at least for the most advanced of them.
Unfortunately our best model doesn’t yield easy interpretation, so we can’t issue precise recommandations as to how to create a blockbuster
The time dedicated to the project didn’t allow us to use more precious information that could potentially be a strong predictors for success of a movie. Primarily, budget information is the one that comes to mind. But other information such as tagline analysis may be useful too.
Also it would be good to analyse a much larger movie base. Here we study 1200 movies, including a large proportion that were well rated. It should be possible to come up with a finer analysis by scrapping more movies, and more diverse as well.
Yet, maybe this is a good thing that we can’t provide clear guidelines as to how to make a successful movie… After all it’s also an art, not only a business. A little bit of unpredictability is good sometimes too!